一、引论·
机器学习定义·
Tom Mitchell:Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E (1998).
机器学习研究问题·
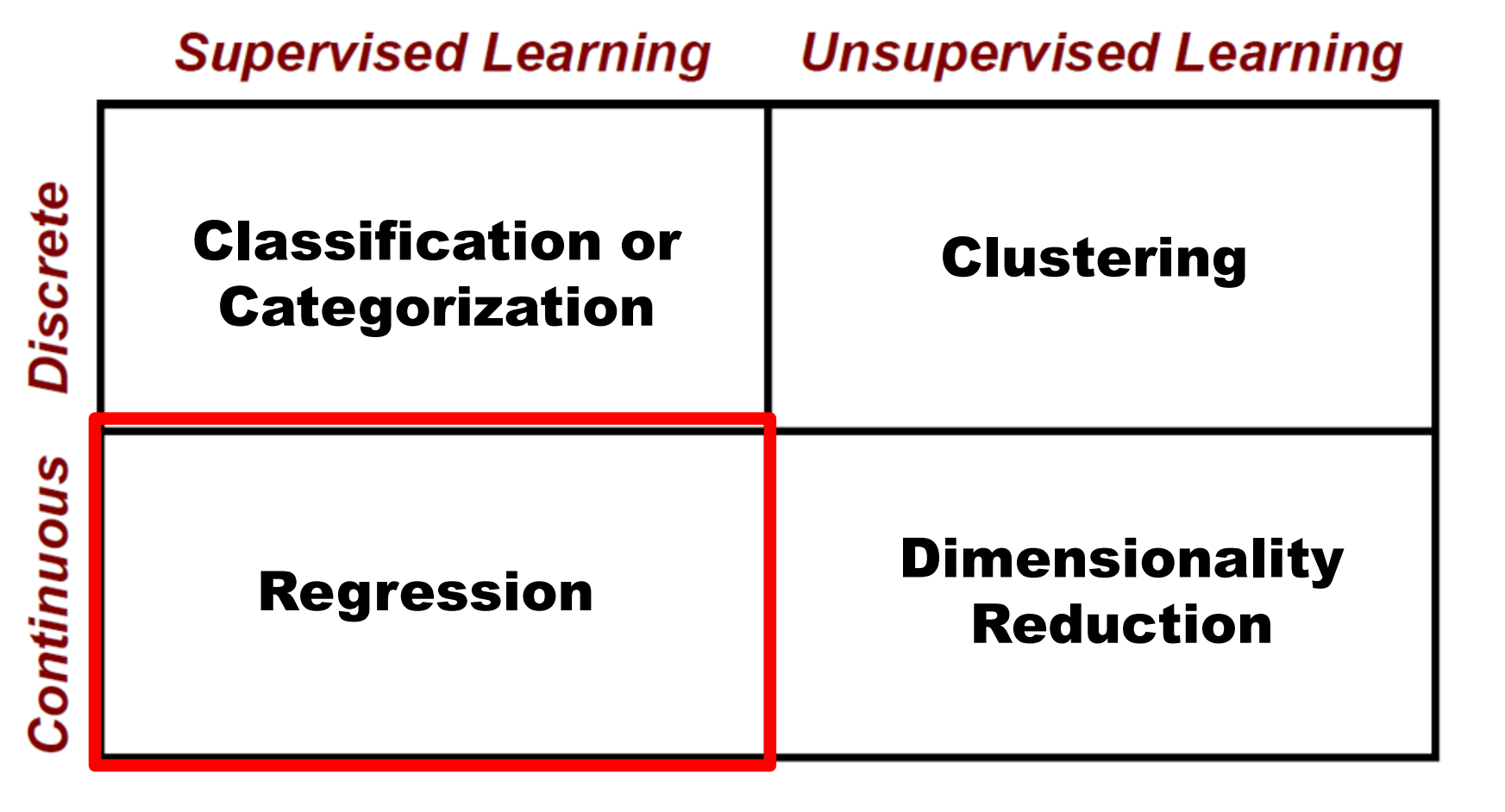
二、模型评估与选择·
误差·
误差 训练误差/经验误差 测试误差/泛化误差
数据集划分·
划分为训练集与测试集,两者尽可能互斥。
保持/留出法**(hold-out)**·
随即划分两个集合,一版2/3为训练,1/3为测试
随机子抽样(random sub-sampling)·
随机选择,保持方法重复K次,总准确率取平均
K折交叉验证(k-fold cross-validation)·
开始时分为k个大小相似的折,训练测试k次,第i次迭代时,第i折用于测试,其余用于训练。
留一法(leave-one-out)·
K折交叉的特殊情况,只给检验集留1个样本
自助法·
有放回等可能地从初始样本D中均匀抽样,采样D次即可产生|D|长度数据集。对于小数据集和集成学习有较好效果。
性能度量·

分类任务中,虽然错误率和精度计算简单,但是当数据类别不均衡时,占比大类成为影响结果的主要因素,不能提供更详细评估。
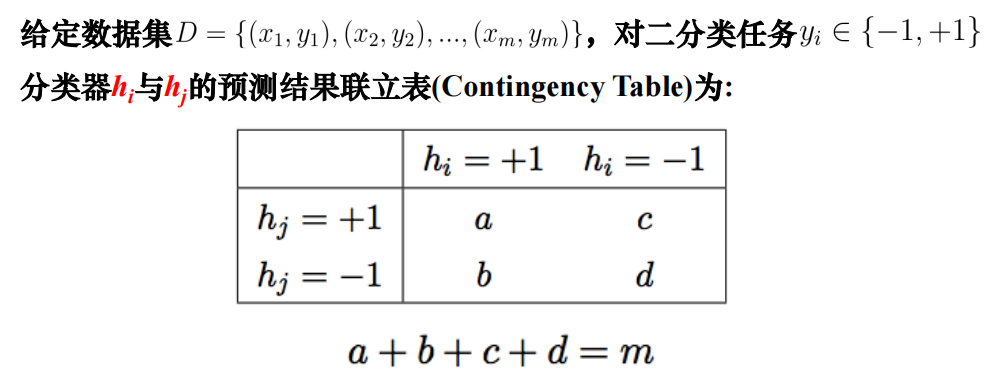
性能度量-混淆矩阵·
包括每一类的正确和错误的样本个数,包括正确和错误的分类。主对角线上的是正确预测的,其他的是预测错误的。
混淆矩阵-两类·
仅有正、负样本2类。用T和F(或1和0)来表征正确错误,P表示正例,N表示反例
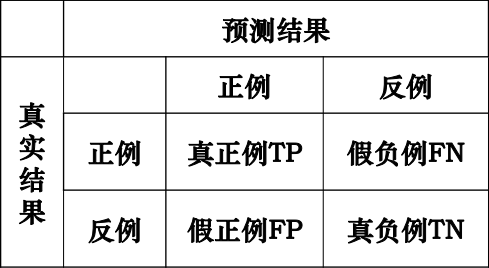
- TP :被分类器正确分类的正元组;期望为P,分类为P:称为真正
- TN:被分类器正确分类的负元组; 期望为N,分类为N:称为真负
- FP:被错误标记为正元组的负元组; 期望为N,分类为P:称为假正
- FN:被错误标记为负元组的正元组。期望为P,分类为N:称为假负


P-R曲线·
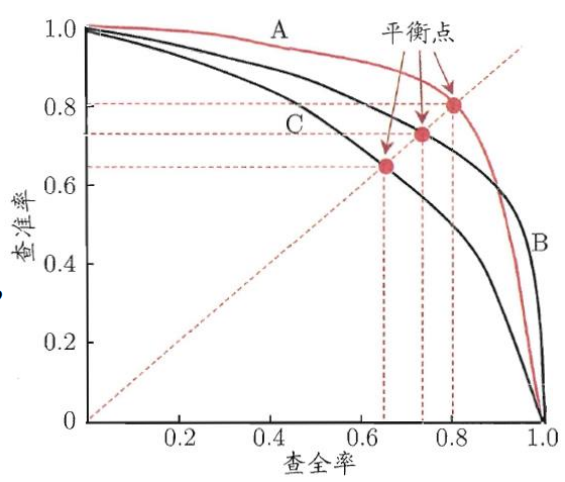
查全率/召回率其实是看所有的正样本中,有多少被成功标记成正的。
查准率则是,判断为正的样本中,有多少是正确的。
查准率与查全率相互矛盾
性能度量-F分数·

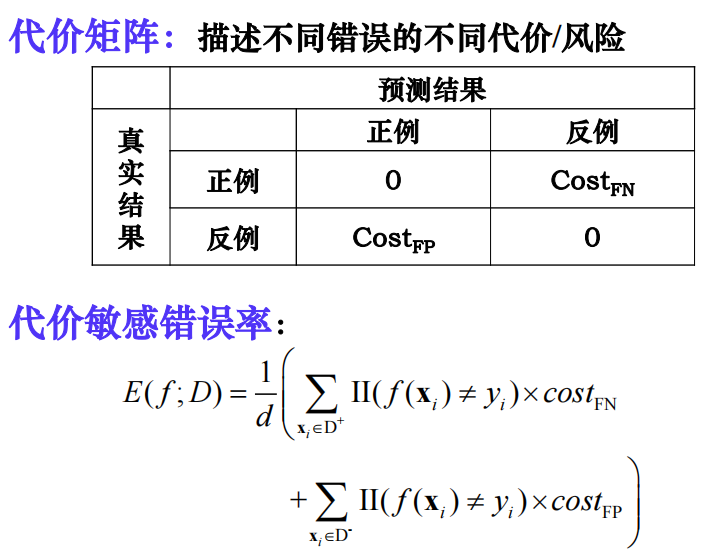
代价敏感性能度量·
三、贝叶斯决策理论·
统计决策理论
基本概念·
样本 每个人的身高体重等信息
类别/状态 例如:男女性别
先验概率 类别比例/出现概率 —— 以往历史数据得到的概率
样本分布密度
类条件概率密度
后验概率 —— 利用最新输入数据对先验概率进行修正后的概率
错误概率
平均错误率
正确率
贝叶斯决策·
基于最大后验概率进行决策(即最小错误率)·
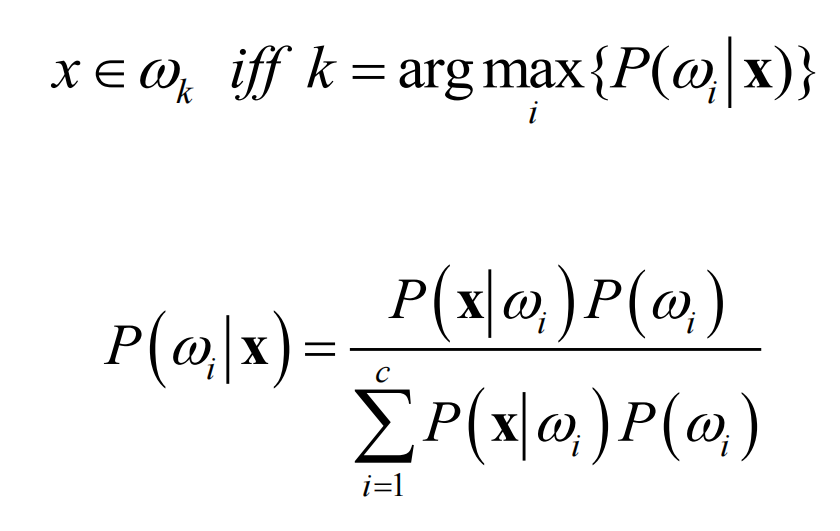
$P(x|\omega_i)$:类条件概率密度
$P(\omega_i)$:先验概率
$P(\omega_i|x)$:后验概率
解决分类问题
最小错误率贝叶斯决策·
对于每一个样本后验概率均选择错误率较小的结果
最小风险贝叶斯决策·
损失函数:对特定的x采取特定的期望损失

朴素贝叶斯决策·
直接根据样本的各个属性发生概率之积来计算
概率密度估计·
参数化方法·
最大似然估计
贝叶斯估计
非参数化方法·
$Parzen$窗法
$k_n$近邻法
四、线性模型·
线性回归·
梯度下降法·
梯度下降—利用所有数据
批处理梯度下降(Batch Gradient Descent)—每次选取一个mini-batch进行梯度下降,一个循环称为一个epoch
随机梯度下降(Stochastic Gradient Descent),又称Online Learning,每次看一个样本
样本量较大时使用
标准方程组法·
直接对损失函数求导得到标准解
样本量较小时使用
线性判别函数·
线性判别函数$g(x)=\omega ^T x+\omega_0$

广义线性判别函数容易带来维数灾难。因此使用线性判别函数的简单性解决问题。利用齐次简化后的线性判别函数
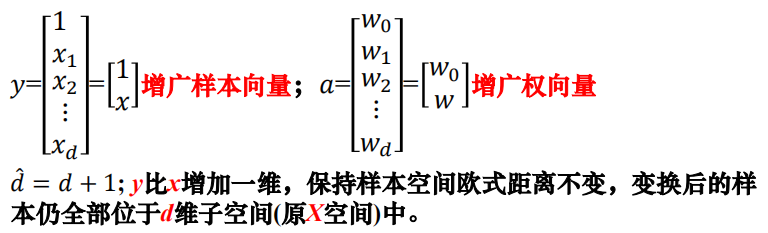
设计分类函数,准则函数,之后求准则函数极值
Fisher准则·
寻找投影方向最好的方向
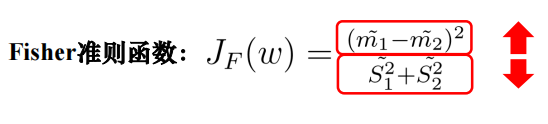
上面的m1/m2是某一类的均值,下面的S1/S2是类内的离散度,即类之间的差别越大,类内差别越小



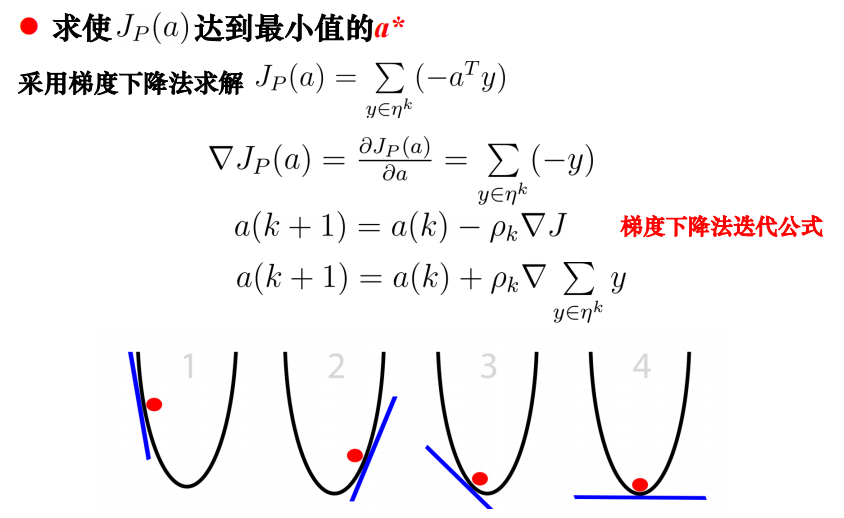
感知机准则·

五、支持向量机·
概念·
SVM从线性可分情况下的最优分类面发展而来。最优分类面就是要求分类线不但能将两类正确分开(训练错误率为0),且使分类间隔最大。寻找一个满足分类要求的超平面,并且使训练集中的点距离分类面尽可能的远,也就是寻找一个分类面使它两侧的空白区域(Margin)最大
线性支持向量机·
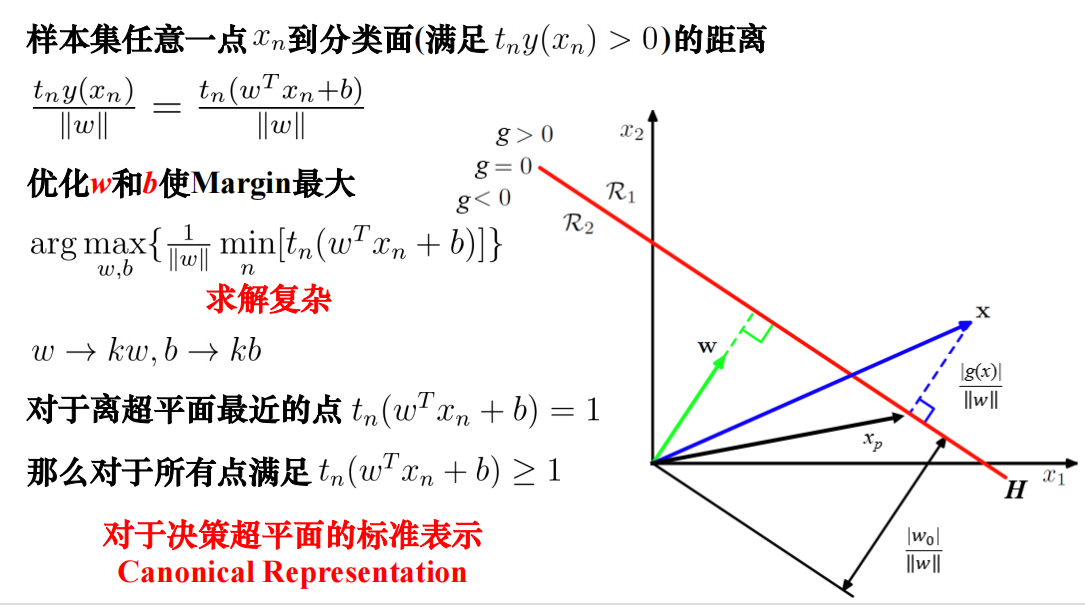

KKT条件·
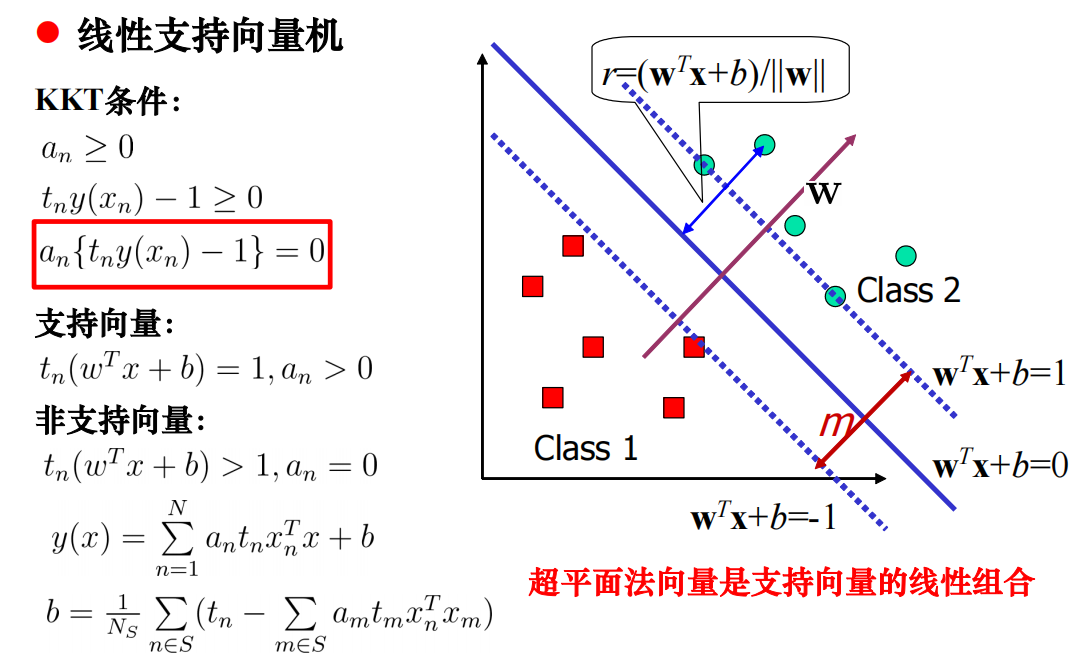
处理噪声和离群点
非线性支持向量机·
用一个固定的非线性映射将特征空间学习的线性分类器等价于基于原始数据学习的非线性分类器
这个非线性映射即为核函数
常用核函数·
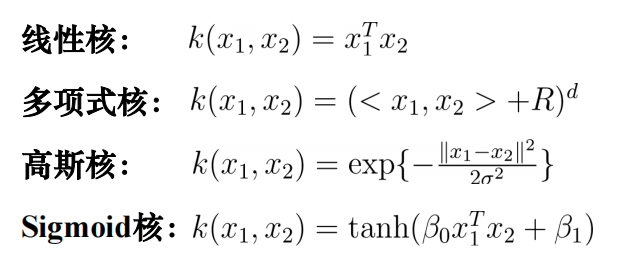
判断是否可以作为核函数·

序列最小优化算法·
序列最小优化算法(Sequential Minimal Optimization, SMO)是一种启发式算法。基本思想是:如果所有变量都满足此优化问题的KKT条件,那么这个问题的解就得到了。
支持向量机工具·
LibSVM: http://www.csie.ntu.edu.tw/~cjlin/libsvm/
六、决策树·
树型结构,由结点和有向边组成
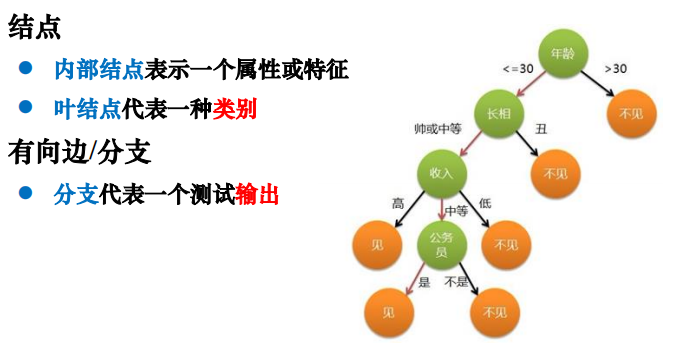
采用自顶向下的递归方法,以信息熵为度量构造一棵熵值下降最快的树,到叶子结点处的熵值为0,此时叶结点中的实例属于同一类。决策树可以看成一堆if-else的规则集合
算法流程·

主要算法·
每个分支结点的样本尽可能属于同一类别,即结点的纯度越来越高
不同目标函数建立决策树主要有以下三种算法:
- ID3:信息增益
- C4.5:信息增益率
- CART:基尼指数
ID3算法·
以信息熵为度量,优先选择熵值下降最快的决策树,即熵值最小的属性
信息熵(Entropy)·

不确定性越大,熵值越大。
经验(信息)熵·

条件熵(Conditional Entropy)·

信息增益·

ID3算法-决策树生成算法·

算法特点·
优点:只要有较好的标注就可以进行学习,可从无序无规则事物中推理出分类规则。分类模型为树状,简单直观容易理解。
缺点:偏好取值多的属性,极限趋近于均匀分布,可能受到噪声或小样本影响,容易出现过拟合问题。无法处理连续值,属性值不完整,不同代价等情况的属性。
属性筛选度量标准·
信息增益率·
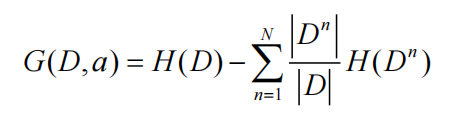
对可取值数目N较多的属性有所偏好。使用如下的信息增益率,可以缓解信息增益准则对可取值数目较多的属性的偏好

C4.5算法采用了这种方式替代了ID3的信息增益。
基尼指数(Gini Index)·

CART算法就采用基尼指数替代了ID3算法的信息增益
剪枝处理(Pruning)·
问题:过拟合
基本策略:
- 预剪枝策略(Pre-pruning):决策树生成过程中,对每个结点在划分前进行估计,如果不能带来决策树泛化性能提升,停止划分并作为叶结点。
- 剪掉很多没有必要的分支,降低过拟合风险,但是由于有些划分可能之后会提高泛化性能,所以可能导致欠拟合。
- 后剪枝策略(Post-pruning):先利用训练集生成决策树,自底向上考察非叶结点,如果将这个结点对应子树替换成叶结点可以提升泛化性能,则替换该子树为叶结点。
- 比预剪枝决策树保留了更多分支,降低欠拟合风险,泛化性能更好,但训练开销也更大。
连续值处理·
采用**二分法(Bi-Partition)**进行离散化。
具体来说,是把从小到大排列的数据每两个相邻的数值的平均作为划分依据,计算相应的信息增益。
缺失值处理·
让样本以不同概率划分到不同的子结点去。即只计算无缺失样本的信息增益,并乘一个无缺失样本占比的系数。
不同代价属性的处理·

延申·
概念学习系统(Concept Learning System, CLS) 1966年Hunt等人提出
分类回归树(Classification And Regression Tree, CART)算法 1984年Breiman等人提出,一种二分递归分割技术
J. R. Quinlan:1979年 ID3/1993年 C4.5算法
多变量决策树
七、人工神经网络·
MP模型·
一种人工神经元的数学模型。


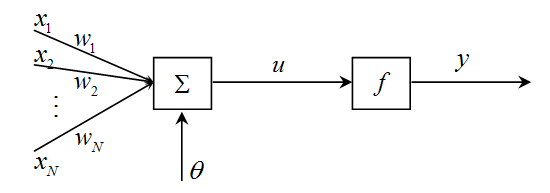
MP模型采用阙值(阶跃)函数作为激活函数。
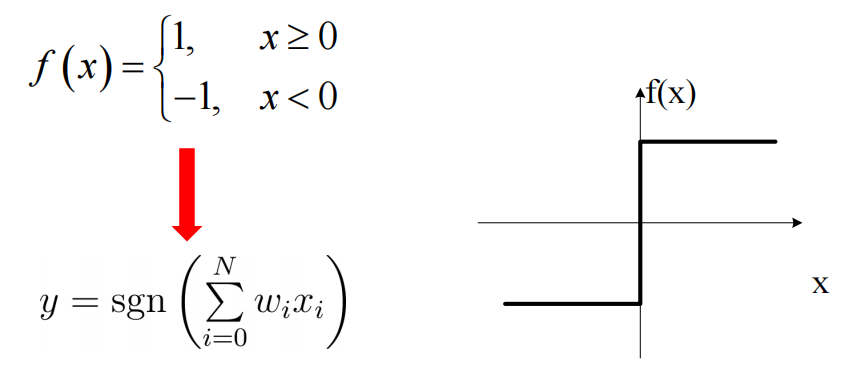
神经元此时可以看成一个线性分类器
激活函数:线性函数,非线性斜面函数,Sigmoid输出函数(S型函数)

感知器·
实际上是一种MP模型,监督学习
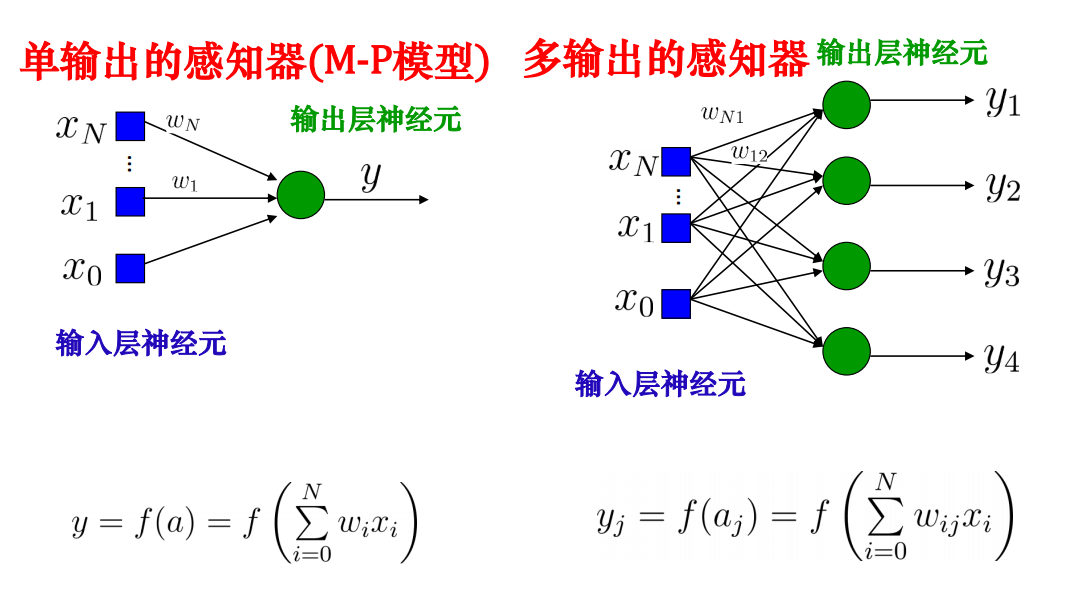
三层感知器可以实现任意的逻辑运算,在激活函数为Sigmoid函数的情况下,可以逼近任何非线性多元函数。
前馈神经网络·
前向传播
反向传播(BP)算法·
以一个三层感知器为例
有训练集D={(x1,t1),(x2,t2),...,(xN,tN)}
隐藏层有M个神经元,激活函数为f1。输出层有K个神经元,激活函数为f2,最终的损失函数为$E(\omega)=\frac 1 2 \sum_{k=1}^K (y_k-t_k)^2$
$z_j=f1(\sum_{i=1}^{N}a_{ji}*x_i)=f1(c_j)$
$y_k=f2(\sum_{j=1}^M b_{kj}*z_j)=f2(d_k)$
方便起见,有如下标记
$c_j=\sum_{i=1}^{N}a_{ji}*x_i$
$d_k=\sum_{j=1}^M b_{kj}*z_j$
则如果需要更新参数,以更新$a_{mn}$和$b_{km}$为例。
先计算$b_{km}$梯度
$\Delta(b_{km})=(y_k-t_k)*f2’(d_k)*z_m$
再计算$a_{mn}$梯度
$\Delta(a_{mn})=\sum_{k=1}^K(y_k-t_k)*f2’(d_k)*b_{km}*f1’(c_m)*x_n$
八、聚类·
一种非监督学习
性能度量·
外部指标·

内部指标·


聚类方法·
K均值(K-Means)·

K-means++·
已经选取了n个初始聚类中心,在选取第n+1个中心时,距离当前n个聚类中心越远的点会有更高概率被选为第n+1个聚类中心。
Kernel K-means·
参照核函数思想,将所有样本映射到另一个特征空间中再进行聚类。
ISODATA·
迭代自组织数据分析算法 Iterative Self-Organizing Data Analysis Technique Algorithm
当某两个聚类中心距离小于某阙值时将它们合并为一类,当某类标准差大于某一阙值时,将其分裂为两类。某类样本数目少于某阙值取消这个过程。
层次聚类算法·
分为自底向上和自顶向下
AGNES算法(Agglomerative Nesting)·
自底向上
初始时,每个样本看作一个初始聚类簇,之后每一步找出距离最近的两个聚类簇进行合并,并不断重复。直到达到预设的聚类簇个数。度量两个聚类簇之间的距离,常用度量方式:
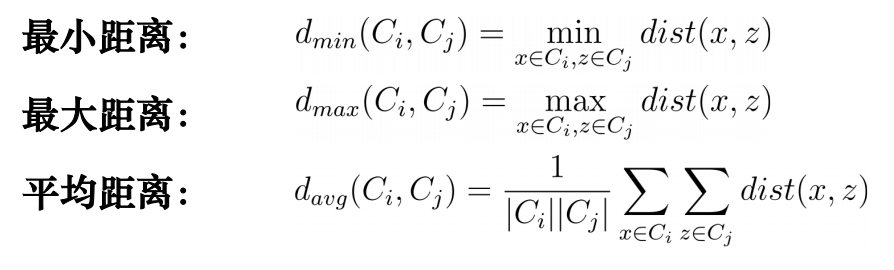

聚类应用·
医学图像-组织分类
遥感图像-地貌分类
BOW模型——词袋模型
网络用户分类
九、数据降维·
数据维度·
点0 线1 面2 体3
数据降维·
高维空间中有很多冗余信息和噪声信息,会在实际应用中引入误差,影响准确率。
降维可以提取数据内部本质结构,减少冗余信息和噪声信息造成的误差,提高应用精度。
降维:利用某种映射将原高维度空间的数据点投射到低维度空间。
降维方法·
主成分分析 PCA·
将原有的众多具有一定相关性的指标重新组合成一组少量相互无关的综合指标。
使得降维后方差尽可能大,均方误差尽可能小
最大方差思想:使用较少的数据维度保留住较多的原数据特性
最小均方误差思想:使原数据与降维后的数据(在原空间中的重建)的误差最小
应用·
利用PCA处理高维数据·
LDA·
LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。什么意思呢? 我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
PCA和LDA区别·
PCA追求降维后能够最大化保持数据内在信息,并通过衡量在投影方向上的数据方差来判断其重要性。但这对数据的区分作用并不大,反而可能使得数据点混杂在一起。
LDA所追求的目标与PCA不同,不是希望保持数据最多的信息,而是希望数据在降维后能够很容易地被区分开。
Kernel PCA·
线性假设一般化,引入核函数。
等距映射·
局部线性嵌入·
十、集成学习·
基本概念·
通过构建并结合多个分类器完成学习任务
又称为多分类器系统,基于委员会的学习
弱分类器:准确率仅比随机猜测略高的分类器
强分类器:准确率高并能在多项式时间内完成的分类器
个体学习器生成方式不同,可以分为两大类方法
- 串行化方法:个体学习器间存在强依赖关系
- 典型算法:Boosting(Adaboost)
- 并行化方法:个体学习器间不存在强依赖关系
- 典型算法:Bagging/随机森林(Random Forest)
串行化方法 Boosting·
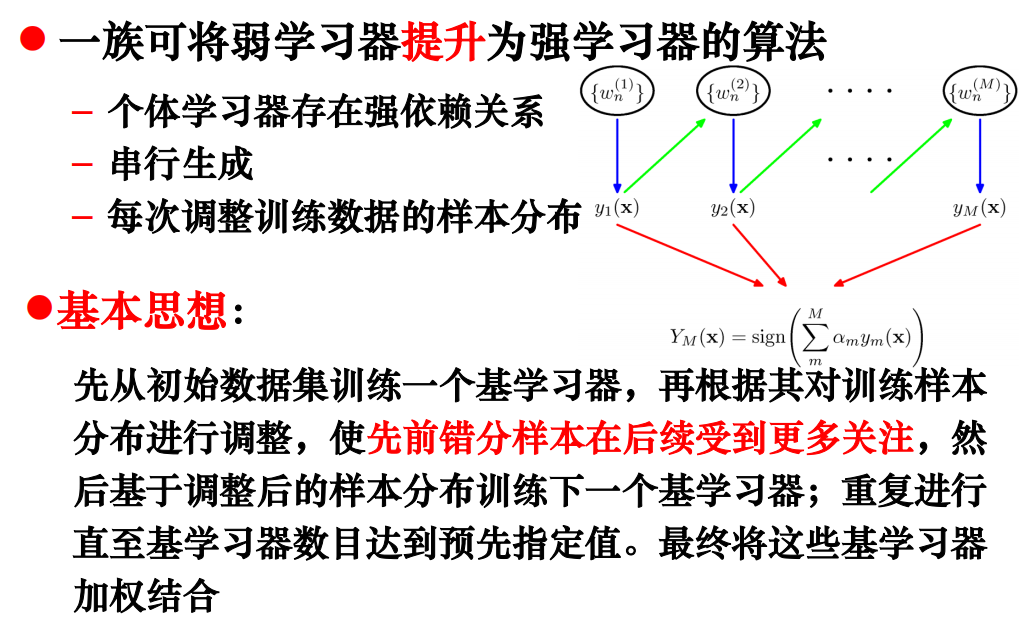
Adaboost算法·

Boosting算法特点·
基学习器能学习特定的数据分布·
重赋权法(Re-weighting)
重采样法(Re-sampling)
特点总结·
主要关注降低偏差,每个模型是弱模型,偏差高,方差低
贪心法最小化损失函数
并行化方法 Bagging算法·
基于自助法采样 (Bootstrap Sampling)

基本思想·
利用自助法采样可构造T个含m个训练样本的采样集,基于每个采样集训练出一个基学习器,再将它们进行结合(在对预测输出结合时,通常对分类任务使用简单投票法,对回归任务使用简单平均法)。
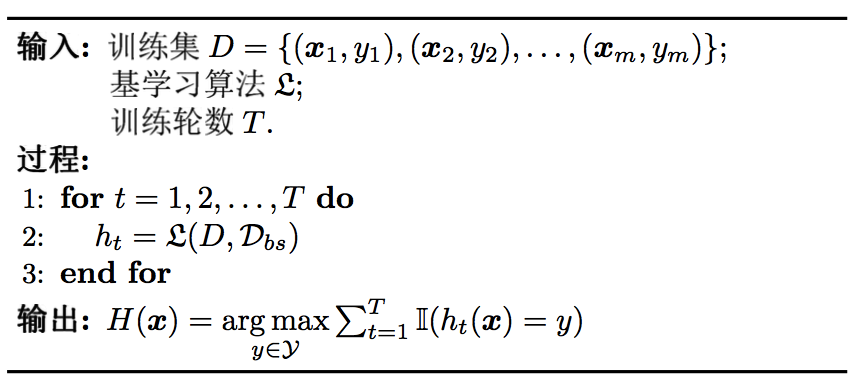
特点·
主要关注降低方差,在易受扰动的学习器上效用更加明显。是强模型,偏差低,方差高
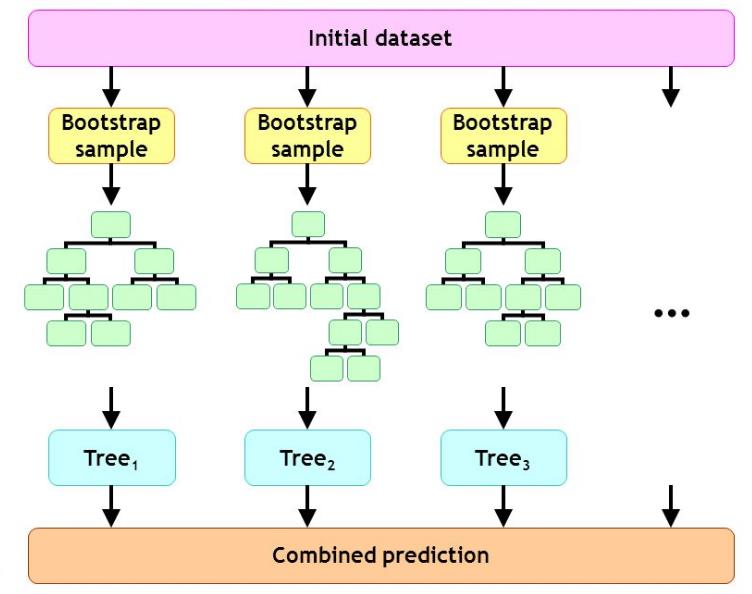
并行化方法 随机森林算法·
Bagging方法的一种扩展变体
Random Forest,简称RF
以决策树为基学习器
训练过程引入随机属性选择

结合策略·
平均法·
简单平均法·
个体学习器性能相近时适用
加权平均法·
个体学习器性能迥异时适用
结合策略—投票法·

结合策略—学习法·
从初始数据集训练初始学习器,初级学习器的输出被当作样例输入特征,继承初始样本标记,从次级数据集训练次级学习器
多样性·
度量集成中个体学习器的多样性,考虑个体学习器的两两相似/不相似性
多样性度量·


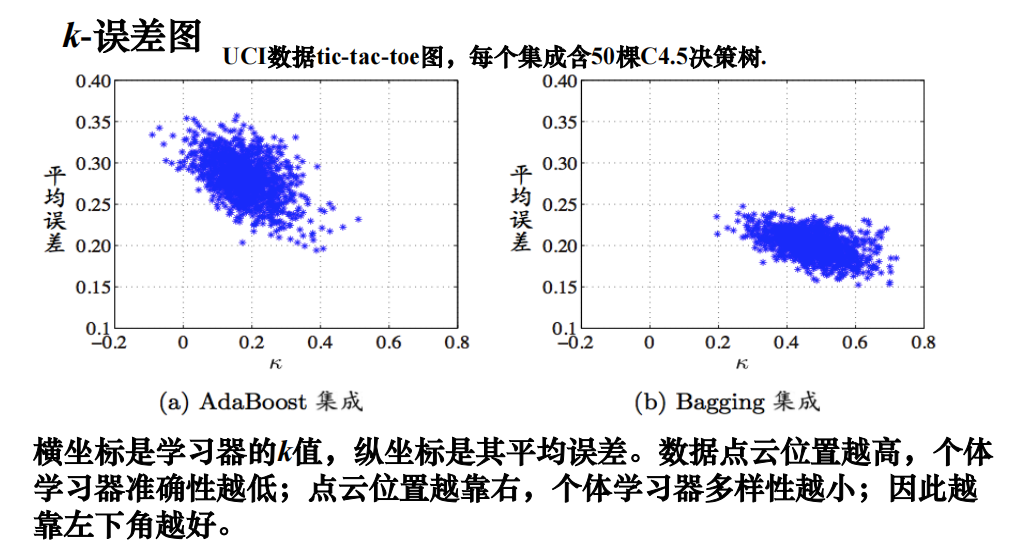
多样性增强·
- 数据样本扰动
-
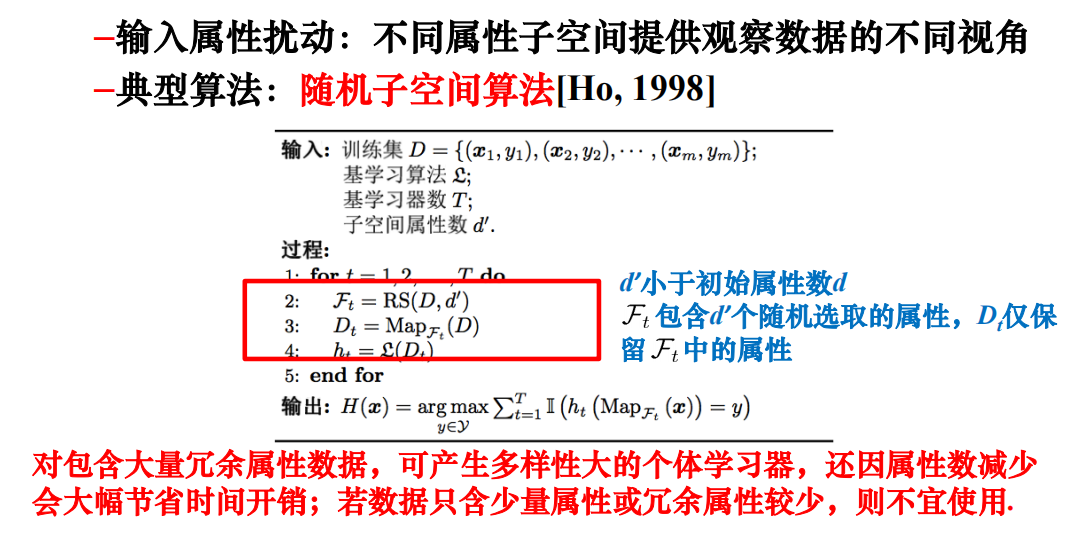
- 输入属性扰动
-
- 输出表示扰动
-
- 算法参数扰动
-
- 不同的多样性增强机制也可一起使用
- Adaboost:加入了数据样本扰动
- 随机森林:同时加入了数据样本扰动和输入属性扰动



十一、半监督学习·
如何有效利用已标记和未标记的样本集
基本假设·

自学习方法 (Self-Training Methods)·

典型代表-最近邻自学习算法·

典型代表-半监督SVM·
直推式支持向量机T-SVM·
针对二分类问题,同时利用标记和未标记样本,通过尝试将每个未标记样本分别作为正例和反例来寻找最优分类边界,来得到原始数据中两类样本的最大分类间隔
典型代表-半监督聚类·
- 必连与勿连约束
- 利用这样的关系进行约束K均值
- 具有少量标记样本
- 直接将初始的有标记样本作为种子,初始化Kmeans的K个聚类中心